

We’ve had a lot of crazy moves this offseason, Eastern and Western Conference alike. All the 2017 signings, from the big names (Gordon Hayward, Chris Paul, Jimmy Butler, etc.) to the slightly lesser (Jeff Teague, J.J. Redick, Jamal Crawford, etc.), beg the question: How has this offseason changed each respective teams’ lineup effectiveness?
The “Fit” Assumption
There have been very informative ways to quantify fit, some by our very own Senthil Natarajan. These approaches seek to answer the question, “How effectively will a certain lineup of players play together?” Alternatively, fit can be used to determine how a player will change once he joins a team with a certain composition and vice-versa.
Read More: Ian Clark can hit open jumpers for the Pelicans
Currently, I don’t have a model that ascertains how a certain player “fits” when he joins a team or if his team’s composition changes through trade (look out for a future post). For right now, I’m assuming that players will take on their most recent “role,” when either they or their team transition. For example, if Hayward was considered a “god” in 2017 by my clustering analysis, he will retain that role on the Celtics in 2018.
The Process
If you don’t care much about #TheProcess, you can skip to the GIF at the end.
I define effectiveness in terms of how much greater the lineup is than it’s opponents in eFG% and points scored. For each of the top 100 most-played cumulative lineups dating back to 2001, I replaced each player with their respective cluster for that year. I then counted the number of times a certain type of player appeared in a lineup, then divided that number by five to yield a “lineup composition” percentage.
Since I’m attempting to predict both the eFG% and Net. Pts of a given line-up, I created a separate model for each task. Alternatively, I could have used one model, but for interpretation reasons, I chose separate models.
In order to determine which player cluster impacts eFG% and Net. Pts the most, I used a simple ElasticNet regression model and examined it’s coefficients. Below is a graph illustrating the results.
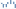
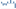
Essentially, the coefficients can be interpreted as such: If we hold the composition of all other groups constant, and increase the percentage of the “gods” group by one unit, we expect to see a net increase of 25 points and a net increase of .12 in eFG%. Using this same method of analysis, we see that the groups “Mostly 3, Little D” and “PnR Bigs” don’t affect the resulting eFG% much. Between the two models, we see that “Gods,” “Offensively Gifted” and “Defensive Guards” player types contribute the most to both fields., whereas other player contributions are negative.
Discussing “Fit”
Just from analyzing the weights above, we can begin to discuss fit. In order to create a team that “works” so to speak, we just need to assemble players such that when they play together, they don’t cause one another to drop off into a category with negative weights. As an example, when LeBron James joined Dwyane Wade and Chris Bosh in Miami, people questioned how the offensive burden would be shared.
From my previous clustering analysis, prior to joining the Heat, LeBron and Bosh were in the “God” and “All-Around Big” categories, respectively. Wade was also in the “God” category prior to teaming up with James. Post collusion, these players still maintained their original player types.
Additionally, prior to joining the Cavs, Kevin Love and LeBron were both in the “God” category. Kyrie Irving, pre-LeBron, was in the “Offensively Gifted” category. After joining LeBron, Kyrie elevate his game that following year and joined the “God” category, but Love downgraded into the “All-Around Big” category. Although not as effective at preserving each individual player’s previous talent, this team composition did not hurt the team as much as it could have.
Imagine a scenario where LeBron joining the Cavs resulted in Love turning into an “Average Big” or a “Mostly 3, Little D” player. Although the resulting Cavs team would be better off by adding LeBron, it’s “fit” wouldn’t be optimal (i.e. not maximizing each player’s potential).
Of course, I’ll need to do more work to fully flesh out this idea, but the groundwork lies in minimizing the amount of negative change a player experiences as a result of changing team composition.
The Projections
In addition to using an ElasticNet Regression model, I sought to add additional predictive ability by adding (commonly called “ensembling”) the predictions of a RandomForest Regressor, a Support Vector Regressor, a Neural Net Regressor and a KNN Regressor. The resulting model produced lower Mean Squared Errors for both the eFG% and Net Pts. predictions.
The following GIF shows how certain teams’ best lineups could change as a result of trades and signings.

The Celtics trade-off eFG% for a gain in Net Pts with the addition of Hayward, while Utah severely suffers. Minnesota makes a huge jump with it’s additions of Teague and Butler, while surprisingly, the Clippers aren’t harmed as much as we would think.
Next: Chris Paul and the complex legacy of the “pure” point guard
Future Work
With this information, I hope to create a web app which would allow one to insert their favorite lineup and see it’s projected value and effectiveness. In my next post, I’ll tackle the concept of “fit” in a more quantitative way.