
")
Immediately after the draft the internet produces scores of “Draft Grades.” Typically the grades are heavily weighted towards the writers’ pre-draft opinion of the different prospects. Occasionally the writer adds some weight to the projected fit of the prospect with the drafting team, which is fine as long as the long view is taken and nobody dings Trae Young for not fitting with Dennis Schroeder (I don’t think people are still doing that kind of thing).
At Nylon, we’re all about the numbers, so I went at the draft evaluation process without the grades and with my draft model instead. Part of what I did, in fact, was to update my draft model based on where in the draft the prospect ended up going. Most teams put a great deal of effort into evaluating talent through scouting, video review, medical reviews, interviews and, yes, analytics. So, unsurprisingly, when I add draft order selected the results of my models the predictions get a bit better.
Running the pre-draft model without the draft selection information and then the model including draft selection order gives me a couple of pieces of information; which players look like reaches/steals according to the model and how does the model reevaluate each player after the draft, who rose or fell the most based on their selection spot? Basically the model gives the benefit of the doubt to each organization of being a typical competent NBA franchise, and for later picks that includes all of the organizations that passed on the player picked too.
Both models are trained on peak rookie contract value as estimated by a combo of box score stats and regularized adjusted plus minus (RAPM), the only difference is the introduction of where players were taken in the draft. I used the BART package in R, a random forest regression that uses a prior and cross validation to reduce overfitting. In the context of the model, this is the plot showing how the draft pick info would affect the projection for a player:
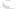
The image shows the effect on a player’s projection as the draft slot gets later with the projection falling until flattening out at a lower level in the late 30’s. The effect in the model is lower than the outright differences in performance by draft spot because draft spot is correlated to other measures picked up in the model, such as age and statistical production in college or international play.
The contrast between the before and after models show that being a steal and changes in estimates after the draft are negatively correlated. In that sense, the post draft model allows us to hedge our bets.
Below are the player’s whose post draft estimate rose the most and some of the biggest “over drafts” by my model’s estimate.

Ayton moves up mostly because of the historic performance of a number one pick. The gap in ordinal spaces between the model’s number four rank and his first overall selection isn’t that big. But, historically, the difference between the top pick’s value and the expected value of the fourth pick is significant, as big as the gap between the fourth and the seventeenth pick.
Jerome Robinson is the biggest reach in terms of rank and value, and consequently the biggest riser in terms of post draft estimate. Reportedly, the Clippers felt like they had to move because he wouldn’t be around later. Maybe they and the other teams looking at Robinson in the middle of the first saw something missed by the numbers, or maybe they projected something that isn’t there. We’ll have to wait a few years, at least, to figure that out.
On the other end, here are the biggest steals and players estimated lower in the post-draft model.

Model favorite De’Anthony Melton was the biggest steal in terms of spots, and shares the second-biggest fall in estimate with eventual No. 27 pick Robert “Don’t call me Bob” Williams. For both players, as outsiders, we have to question what all the teams that passed on them know that we do not. Still some past fallers like Draymond Green turned out OK, so it’s appropriate that the model hedges its estimate. For Williams the post draft model moves his expected rookie contract peak down from +1.6 to +0.9, for Melton the estimate moves from +1.8 to +1.4, both of which would still be huge steals at that production level.
The biggest downward estimate is for Dzanan Musa, moving from +0.6 projection to just below average -0.3, Musa gets hit a bit more because his most attractive assets, youth and scoring are best correlated with being a draft pick, so including the pick order information lessens their impact, a double blow to his projection.
There’s no perfect way to summarize how much of a steal or reach any particular pick is. Comparing the separation in rank order from the model to the draft overstates the the difference between the 35th-best player and the 45th-best player compared to the third-best player and the 13th. The gaps in talent at the top of the draft are typically larger than at the back, where differences can be pretty fine grained.
Comparing the projected value of the player taken with the historic value of the pick is a bit better, but even here there’s the danger of overestimating the value of a relative hit on a late pick. The expectation of a late second-rounder is pretty much at the replacement level, meaning the kind of player that could be picked up on league minimum or even ten-day contract. Outperforming that spot by an expected two tenths of a point isn’t moving the needle much. So, I also added an estimate based on the model projection and the model’s past error rate of the odds of the player being a +2 in terms of efficiency, a subjectively chosen cut off for an impact player. I also added the difference between their pick selection’s usual odds of reaching that level.
Next: WNBA team ratings and the Lynx's slow start
I included all of the players from the first round I had data available for and the second-rounders that project with the best chance of having an impact:
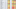
While there are a couple of different ways to look at who added or lost the most value on draft night, the “Change from Expected Value” and “Difference in Odds from Pick” of being an impact player are at least a place to start.