
")
By now most basketball fans with any interest in analytics know that opponent 3-point and free throw percentages are among the most noisy numbers around. That’s especially true over the relatively small sample of games here in the early part of the season.
But just because jump shots are among the most variable actions on the court doesn’t mean that they’re the only source of variation. To examine that idea, I decided to compare the variation by team in Dean Oliver’s Four Factors on both offense and defense at this stage of the season to the amount of variation after a full season last year.
Using Basketball-Reference’s team tables, I calculated the standard deviation between teams for each factor last year and this year as of Monday morning. Then I simply divided the year to date number by the full year. The bigger the ratio is the more variance there is in the current Four Factor numbers, and therefore the more regression we can probably expect for outlier teams.
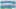
Somewhat surprisingly offensive free throw rate is showing the most relative variation at this stage. That’s followed closely by opponent effective field goal percentage and defensive rebounding percentage.
That information can then be used to make estimates of where teams can expect regression and if there are teams that appear more vulnerable than others. Setting a prior with a modest adjustment towards last year’s performance based on the historical year-to-year carry over for each factor, I estimate an expected regression for each factor. For example, the average year to year R^2 for offensive effective field goal percentage has been around .40 for the last few years, while defensive effective field goal percentage has been about .15.
The team prior helps make better estimates about the likely progression of stats like the eFG% of the Golden State Warriors, but it’s a but of a blunt tool, especially for high roster change teams.
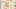
The conditional formatting has been added to highlight the outliers. You can see how much more regression the numbers indicate will come in free throw percentage. The Kings should be able to increase their free throw rate on offense just by getting accidentally bumped into a couple more times by the rookies they’re likely to face in garbage time.
There are a few other interesting predicted regression candidates like the Bucks abysmal offensive rebound percentage which will have to snap back without Greg Monroe going forward, or the Timberwolves free throw rate by opponents which has probably been unsustainably low so far.
Next: Nylon Calculus -- Orlando Magic and volatility beyond the arc
The Four Factor regressions above aren’t necessarily predictions. They don’t explicitly take into account who has been on the court for each team. They should, however, give a sense of how out far the norm team’s early season performance has been in areas other than shooting or opponent’s shooting from outside.